
I while back, I was looking for a fun project to test open-source best practices (docker, GitHub Actions, etc). I came up with “rickroller”, the perfect tool to rickroll your friends like a pro!i
In this article, I want to share with you my vision of a perfect RickRoll prank (demo ⮕ https://rroll.derlin.ch), and some interesting aspects of its implementation. If you want to learn more about open-source best practices, have a look at the README (⮕ https://github.com/derlin/rickroller).
- What is RickRolling?
- My vision of a perfect rickroller
- The final result
- How to Rick Roll your friends like a pro
- The deployment
- Conclusion
(TOC generated with bitdowntoc using the Gitlab preset and the anchor prefix option set to heading-)
What is RickRolling?
I am sure you already got RickRolled at least once in your life. But for the lucky ones out there, Rick Roll is an internet prank that started around 2007 on online bulletin boards like 4chan and Reddit, where users would post a link that unexpectedly directed to a video of Rick Astley’s “Never Gonna Give You Up”.
Since 2007, the prank bubbled and it is now everywhere. There are so many fun websites and tools available around Rick Roll, such as r.mtdv.me, a Rick Roll Link generator, or rickrollrc, a Bash script playing the video with ANSI 256-color coded UTF-8 characters + audio (if available). There is even an AntiRickroll Chrome Extension!
My vision of a perfect rickroller
Most of the tools out there are based on disguising a link that opens directly on Rick’s video. Which is fine, but lacks subtlety. I wanted to go further.
The idea? Have people think they are on a real (and interesting) website before getting redirected. More precisely, here is how I envision the prank:
-
you send a link to a friend that looks like the shortened URL of a very interesting web page,
-
the friend opens the link and lands on what looks like the real stuff,
-
the friend interacts with the page (click, scroll), and BOOM, RickRoll!
This makes for a more subtle and fun Rick Roll, don’t you think?
To make this prank possible (because of course I implemented it), I need a web server with three different views:
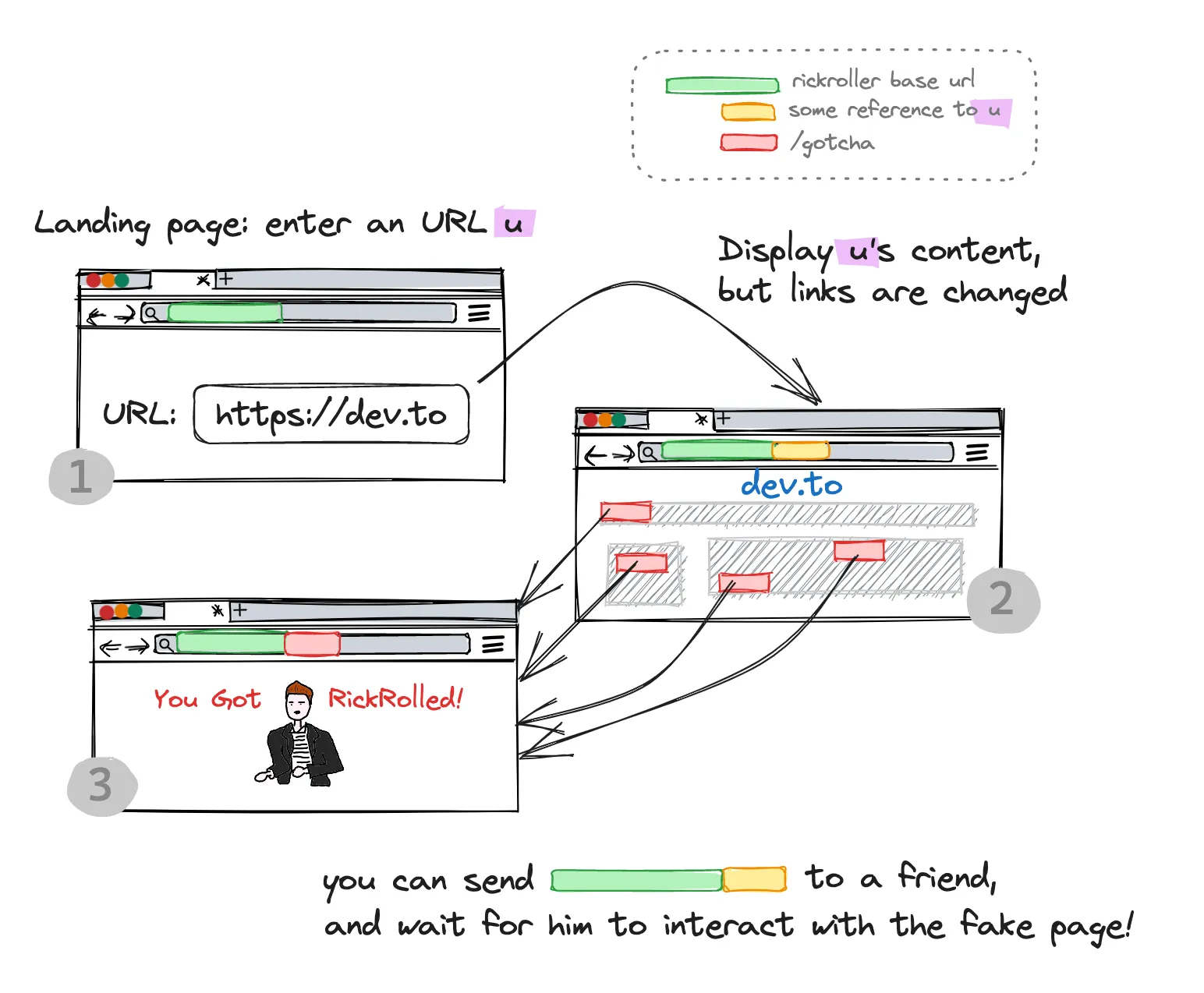
View 1 is the prankster interface, where he can choose which original URL (web page) to fake. In view 2, the server determines the original URL to masquerade (e.g. thanks to a query parameter - keep reading!) and renders the original URL content but with slight changes making it redirect to view 3 upon interaction. That’s “rickroller”!
The final result
My Rickroller implementation is a simple Python Flask app. You can test it at https://rroll.derlin.ch (hosted by the awesome PaaS ♡ Divio ♡).
Here is the view to create a rickroll (view 1):
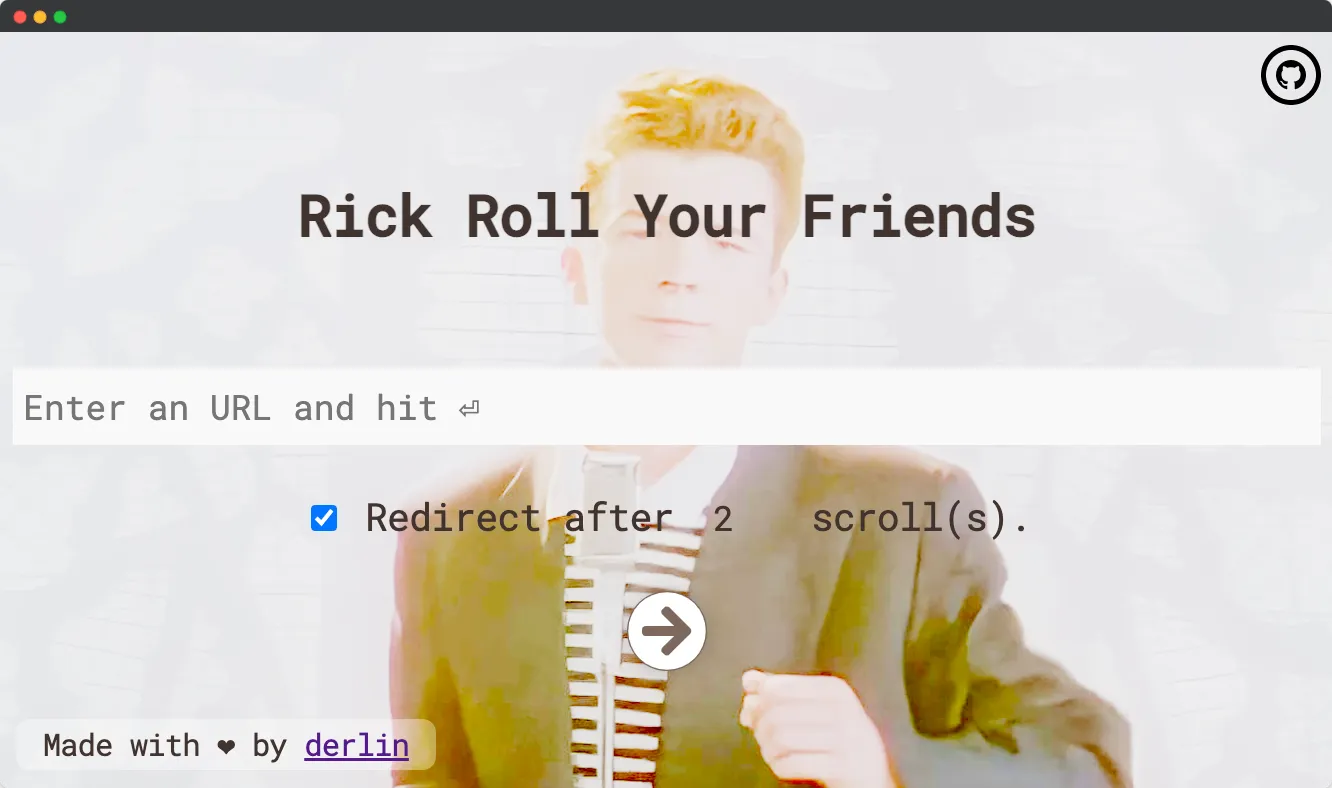
Try to enter a URL, then interact with the fake page. You should end up on:

Cherries on the cake, the social preview from the original site shows up when you share a phony link. Here is the result of sharing the malicious https://dev.to URL on Telegram:
(Note: the first prototype was on tinyurl.eu.aldryn.io, and later moved to rroll.derlin.ch)

The best is to try it yourself, it will become clearer. The code and many more details are available on GitHub ⮕ https://github.com/derlin/rickroller.
IMPORTANT: the fake links may become obsolete after a few days.
How to Rick Roll your friends like a pro
So, how did I end up with this? I won’t go into all the details, but let’s dive into some interesting points.
Rendering the “original” page
The first challenge is to render a “clone” of the original URL. We can easily get the HTML from the original URL and return it. However, without modifications, it will be completely broken. Why?
-
most pages use relative links (to images, scripts, CSS, etc).
-
some pages load resources protected by CORS - cross-origin request sharing.
For 2, we can’t do much. For 1, though, my first idea was to go through all the links in the HTML and absolutize them (prepend the original URL to it). The full implementation is available here, but basically:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def absolutize(tagname, attr, soup, url):
for elt in soup.find_all(tagname, **{attr: True}):
elt.attrs[attr] = urljoin(url, elt.attrs[attr])
# get the original HTML
response = requests.get(original_url)
if response.status_code != 200: raise
soup = BeautifulSoup(response.text, 'html.parser')
# absolutize all important tags
args = [soup, original_url]
absolutize('a', 'href', *args)
absolutize('link', 'href', *args)
absolutize('script', 'src', *args)
absolutize('img', 'src', *args)
# + fix 'img' with 'srcset', or else images using it
# won't loadGood, but complex and error-prone… And it won’t work for relative URLs located inside scripts or CSS! How could we make it better?
Meet the <base> tag!
The
<base>HTML element specifies the base URL to use for all relative URLs in a document.
Yup, just adding a <base href="{base}"> in the header can replace all the code from my first attempt. Cherries on the cake, it will also work for relative links in CSS files!
def absolutize(soup, url):
# ... add <head> if missing ...
base = soup.head.find("base")
if base is None:
tag = soup.new_tag("base")
tag.attrs["href"] = url
soup.head.insert(0, tag)
else:
base.attrs["href"] = urljoin(url, base.attrs["href"])Done :)
Instrumenting the page (ie. redirect)
Now that we rendered a clone, it is time to modify it so it redirects to a “rickrolled” page.
At first, I just wanted to redirect the user on click. I thus naturally thought about changing all the links on the page to some Rick Roll video.
Since I already got a “soup” (BeautifulSoup object), I can easily alter all the <a> elements in the body. This last part is important because the <head> contains links to resources (CSS, js, etc.) that need to be loaded properly for the page to look remotely normal.
for a in soup.find('body').find_all('a'):
a.attrs['href'] = __RICK_ROLL_URL__Simple enough, but the result is far from perfect…
Most problems are caused by this increasingly in-vogue habit of using <a> elements for “page logic” instead of “real navigation”: opening a popup, animating a menu, controlling accordions, etc. In this case, changing the href breaks the original behaviour (the menu doesn’t work, or the accordion stays closed) and doesn’t redirect the user either (because of a sneaky JS event handler in the original page calling event.preventDefault on click).
So, how do you ensure any click on an a element redirects to Astley’s without breaking the page? Javascript!
Instead of changing links, I can insert a JS script that hijacks all click events and redirects to the rickrolled page. If I add it at the very bottom of the page, it will take precedence over everything else.
The Javascript looks like this:
document.addEventListener("DOMContentLoaded", function(event) {
document.addEventListener("click", e => {
e.stopPropagation();
e.preventDefault();
window.location = "%s"
}, true);And can be inserted as the last child of the body with:
tag = soup.new_tag("script")
tag.attrs["type"] = "text/javascript"
tag.string = __JS_SNIPPET__
soup.body.insert(len(soup.body.contents), tag)I went further to also redirect on scroll. I won’t talk about it here, but have a look at the code if you are interested.
The “You got rick rolled” page
I talked about redirecting a lot. But redirecting where?
Usually, a RickRoll means redirecting to a YouTube video. Apart from choosing one from the zillions available, there are two things I don’t like: advertisements and mobile behaviour. On mobile, YouTube links (slowly) open in the YouTube app, tipping the prankee before the video even starts.
So, I will redirect to a page of mine, which plays the rickroller video.
I first thought of using a video embed, such as a YouTube embed. However, did you know it is now nearly impossible to autoplay a video with sound? From Chrome’s blog:
web browsers are moving towards stricter autoplay policies in order to improve the user experience, minimize incentives to install ad blockers, and reduce data consumption on expensive and/or constrained networks […].
In Chrome, autoplay with sound is only allowed on very strict conditions and always requires some action from the user. All other major browsers are implementing similar policies. This was a huge bummer. No sound it is!
Even worse, the &autoplay=1 parameter on YouTube embeds is buggy as hell: the video started neither on my mobile phone nor my Vivaldi browser. Instead, I got a dumb preview with a play button. I played with other sources providing embeds for the Astley video, but none offered a good enough experience. And more problematic, those obscure websites could go down anytime.
But wait, if a video doesn’t autoplay, a GIF definitely will! If we can’t have sound anyway, a good-quality GIF is as good as any. I thus ended up using a giphy Rick Roll GIF embedded into a very simple web page. It worked perfectly for a while, until the GIF disappeared from giphy, leaving in its place:

To avoid another abrupt disappearance, I downloaded a gif from tenor.com that is now served directly by my server. This is what you see in the final result: http://rroll.derlin.ch/gotcha
The URL shortener disguise
For rickroller to work, the original URL needs to be retrievable in some way from the URL that is shared with your friends (view 2 in the schema), so that rickroller knows what to instrument+display. I can’t use sessions, since the URL is meant to be shared.
The easiest is to use a query parameter: ?url=<escaped-url>. It works, but asking a friend to click on an URL that looks likehttps://some.server.com?u=https%3A//discuss.kotlinlang.org/t/react-in-kotlin-js-what-i-learned-long-but-useful-read/16168 is unlikely to land.
Without adding a layer of persistence, there is however nothing we can’t do: there is no lossless compression that exists for URL strings… If I have a database, though, I could disguise rickroller into an URL shortener!
The idea is simple: when a prankster inputs a URL in view 1, I generate a unique (and short) UUID for it and store the tuple (URL, UUID). The prankster can then use https://some.server.com/t/UuIDxxxx . When the prankee requests https://some.server.com/t/UuIDxxxx , a simple lookup for UuIDxxxx in the database returns the original URL that rickroller can then display.
Since I didn’t know how and where I would deploy the final version of RickRoller, I decided to provide multiple persistence layers:
-
SQLite in-memory → can be used for local testing,
-
SQL-like (SQLite, PostgreSQL, MySQL),
-
MongoDB (only because mongodb.com has a free plan!)
Avoiding SSRF attacks
Since rickroller does HTTP GET on URLs provided by the users, it is a perfect target to Server-Side Request Forgery (SSRFs).
To give you an example, let’s say rickroller is deployed on an AWS EC2 instance and a malicious user passes the URL http://169.254.169.254 - the metadata service. The user doesn’t have access, but rickroller does! This could leak very sensitive information (security groups, user data, …). If this is unclear, [Hacking the Cloud] Steal EC2 Metadata Credentials via SSRF gives a more thorough explanation.
Long story short, I need some kind of security in place. The easiest is to simply deny any “private” URL. But checking the URL provided by the user is not enough! Why? Because by default requests.get() will follow redirects. A hacker could set up a small server with a public address that answers with a redirect to a private URL!
My solution is thus:
-
do the
requests.getcall, and record the history (that is, all the potential redirects, or hops) -
ensure that no private URL is found in the history
Here is the code:
from ipaddress import ip_address
from socket import gethostbyname
from urllib.parse import urlparse
import requests
def __ensure_is_safe(url: str):
hostname = urlparse(url).hostname
if hostname is None:
raise Exception(url, f'Could not extract hostname from "{url}"')
ip = gethostbyname(hostname)
if ip is None or ip_address(ip).is_private:
raise Exception(
url,
f"{url} maps to an unknown or private ip address: {ip}.",
)
def safe_get(url):
response = requests.get(url, timeout=30)
[__ensure_is_safe(r.url) for r in response.history]
return response
print(safe_get('https://dev.to'))The deployment
With all this in place, time to deploy. I manage the release cycle and the publication of the docker images (ARM + AMD) to DockerHub with GitHub Actions.
I have one instance running on Google Cloud Run that uses the free MongoDB database from mongodb.com. I can redeploy it at any time using a manually triggered GitHub Action. However, since I do not want to invest too much into it, I use the cheapest Cloud Run instance and everything is slow (the instance stops and starts for each request).
I explain everything at length in the README if you want more details.
For the actual demo, I host another instance on divio.com, which is an awesome PaaS with far better response times. More precisely, divio deploys rickroller on AWS for me (I chose the European region), taking care of all the heavy work (CloudFront, DNS, backups, security, etc). It also comes with a nice UI and CLI.
Conclusion
What started as a dumb and easy project (code-wise) turned up to be a bit challenging. I really enjoyed going the extra mile (deployment, release management, etc) and learned a lot along the way. I can only encourage you to start your own fun project and do the same!
I hope you enjoyed the read and learned something. Please, go ahead and play with the demo: Long live RickRoller!
With love, @derlin