I am working for a PaaS (Platform As a Service), meaning that we not only have our internal apps to maintain, but we manage thousands of client apps that are all different and yet have to run on the same platform.
How? At Divio, we strictly follow the Twelve-Factor App and have built our platform so that an app adhering to the same standards (plus a few conventions) can be deployed in minutes.
Initially published by Heroku engineers in 2014, these principles are best practices that guide the design of “Web Apps” to boost flexibility, scalability, maintainability, security, and [… ask ChatGPT for more …]. They make it easier to deploy anywhere, especially in the cloud.
I had trouble understanding the benefits until I practically witnessed the power of those 12 simple best practices. Some I already applied intuitively (without knowing why), and others opened a new way of designing and architecting software. Sticking to those principles is a game-changer, as they simplify and resolve many common problems and pitfalls.
I’ve been dying to talk about them for a long time, so without further ado, let’s dive in!
(I will stay quite generic in this article, let me know in the comments if you want a follow-up with more practical examples).
The Twelve-Factor App principles:
- I Codebase
- II. Dependencies
- III. Config
- IV. Backing services
- V. Build, release, run
- VI. Processes
- VII. Port binding
- VIII. Concurrency
- IX. Disposability
- X. Dev/prod parity
- XI. Logs
- XII. Admin processes
I Codebase
one codebase tracked in revision control, many deploys
An app should only have a single codebase, and each codebase must be using a version control (git, mercurial, svn). If an app is split into multiple codebases, then it is not an app, it’s a distributed system - and the factors should apply to each app composing it.
“Deploys” refer to running instances of the app. Many deploys mean the same codebase must be used in all environments - in production(s), locally, in QA, etc.
II. Dependencies
Explicitly declare and isolate dependencies
First, an app should never rely on implicit, transitive or system-wide packages, but instead declare all its dependencies (including their version and possibly an SHA) using a dependency manifest. Examples are pom.xml in Java, requirements.txt or pyproject.toml in Python, Gemfile in Ruby, package.json in Node.
Second, dependencies should be isolated from the underlying system on which an instance runs. This is typically achieved using tools such as virtual environments in Python and containerization (Docker).
This factor thus ensures consistency and portability. By making the app’s environment predictable and reproducible, it suppresses the “it works on my machine” conundrum and streamlines the whole flow (onboarding new developers, boosting the stability of build & tests in CI, deploying on new environments, etc).
III. Config
Store config in the environment
Anything that can vary between deploys should be read from environment variables. Config usually entails:
-
connection information to backing services (database, caching layer, …)
-
credentials to external services (Facebook, AWS, kubectl, …)
-
other configurations: hostname, size of the thread pool, timeouts, etc.
Strictly separating config from code allows the same codebase to run in widely different environments (locally, in staging or QA, in production(s)). Environment variables are a simple construct supported everywhere that can be managed securely and are easily updated. Thus, the configuration can be adjusted dynamically at any time just by restarting the app. This makes the code flexible, portable, and well-suited for CI/CD. Moreover, it avoids the mistake of committing sensitive information!
Some additional tips on environment variables
- Avoid the use of default values when reading configs from the environment. Always be explicit about config in every environments makes it clearer and prevents mistakes. If something is missing, crash early.
- Prefer long, descriptive names, and clearly state the type or unit expected. For example,
CACHE_READ_TIMEOUT_SECONDS=5. - Group similar configuration using a prefix, not a suffix. This way, you can easily sort through your configurations (
env | sort). - Simplify local development by taking advantage of
.envfiles (e.g. a committedbase.envand an uncommittedsecrets.env). If you are using docker, they are easy to source and if you are not, consider tools such as direnv.
IV. Backing services
Treat backing services as attached resources
A backing service is any service the app consumes as part of its normal operation. This may include databases, caching systems, SMTP servers, etc. Those services should be accessed solely via the network using config(s) stored in the environment (see III. Config). Here is an example config for a database (DSN stands for Data Source Name): DATABASE_DSN=postgresql://user:password@hostname/db_name).
Treating all backing services the same way, the app doesn’t differentiate between local and third-party services. It doesn’t matter how the resource is managed or where it is running, as long as it is accessible over the network and complies with the expected protocol. This brings loose coupling and flexibility, as backing services become interchangeable: a database may be swapped from an on-prem instance to an AWS RDS database without any code change, while locally, the app can connect to a database running on Docker.
Design for flexibility, but only if required
Ideally, your app should settle on one backing service implementation (e.g. PostgreSQL for database). However, if you start having to support multiple implementations of a service, rely as much as possible on standard protocols and connection libraries (e.g. an ORM). If this is not enough, switch drivers at runtime with the strategy and bridge design patterns. Other design patterns (dependency-injection) are also handy!
IMPORTANT: A Twelve-Factor app should be stateless (VI. Processes) with every persistent information stored in backing services. This includes the filesystem! If you use the filesystem for more than temporary operations or static assets loading, consider object storages such as MinIO and S3.
V. Build, release, run
Strictly separate build and run stages
The lifecycle of a codebase should follow three separate, non-overlapping steps: build, release, and run, each with a decreasing level of complexity. The build compiles the code into an artifact (e.g. an executable, a docker image). The release adds the configuration for a specific environment. The run starts the instance (or restarts it during a scale or after a crash).
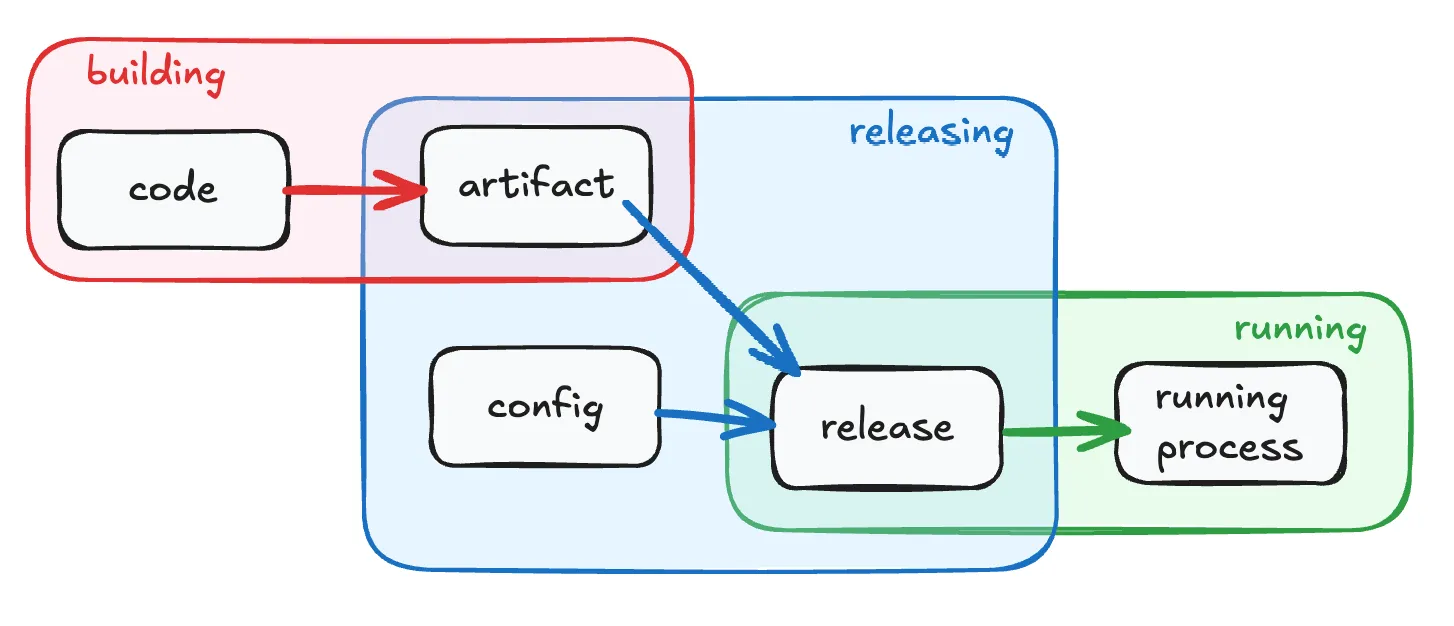
For traceability, each release should be immutable and uniquely identified. This way you can reproduce any version of your application consistently, making debugging, deployment, and scaling easier.
How we do it at Divio
The way we separate those steps at Divio is a good example, so let me give you the gist.
At Divio, each environment tracks a specific branch of a git repo and has a settings section for you to configure environment variables. When you click the deploy button, what we do is:
- build: we clone your repository and create a build image (the artifact) from your Dockerfile.
- release: we build a new release image that inherits from the build image and adds all the environment variables defined in the settings at the time (that is, we build a Dockerfile containing only a
FROM build-imageand one or moreENV XXX=YYYdirectives). In other words, your current environment variable settings are frozen within the release image. Each release has a unique, incremental build number. - run: we simply start one or more containers from the release image. Those containers can be scaled and moved around easily as the release image is self-contained!
VI. Processes
Execute the app as one or more stateless processes
An app should consist of one or more Unix-like processes that can be started and stopped anywhere at will. To make this possible, each process must be disposable, strictly stateless, and share nothing.
In other words, all persistent data must be stored in backing services (IV. Backing services). Memory and filesystems may only be used for transient, temporary, and single-process operations. Processes should behave the same whether they all run on the same machine or in another part of the world.
This makes the app highly resilient and easily scalable.
VII. Port binding
Export services via port binding
The app should be entirely self-contained, and expose its functionalities by binding to a port.
Self-contained stresses an app should not rely on any pre-installed application on the running environment. A web or WSGI application should thus ship with its own server (Apache, Nginx, …) instead of relying on an external one. This is an extension of II. Dependencies.
Binding to a port means the app is accessible via a URL (or another locator such as a web socket address) and can itself be turned into a backing service for another app.
The port is the contract with the execution environment and the app should not care about anything else - such as exposing the port to the outside. It means the app may be accessed directly during development (e.g. https://localhost:<port>/). At the same time, in production, a routing layer takes care of mapping a public domain (and handling SSL termination) to the app’s exposed port. The app itself should never handle the routing directly - it is the job of the execution environment.
Note that it doesn’t only apply to HTTP/HTTPS: nearly everything can run by listening to a port for incoming requests!
VIII. Concurrency
Scale out via the process model
Processes are first-class citizens. An app should be designed to handle multiple tasks simultaneously via the process model. Instead of managing multiple threads or processes from within the app, each type of work is assigned to a separate process. Those processes can in turn be moved around and scaled up and down as needed (VI. Processes).
For example, a typical web application is composed of web processes to handle the HTTP requests, worker processes to run long-running background tasks, and cron processes running scheduled tasks. Processes can even be more specialized: a set of workers for time-sensitive tasks versus low-priority workers.
This specialization of tasks means each process type can be optimized for its particular function (e.g. more CPU time for high-priority workers or running low-priority workers on cheaper hardware) and can be scaled separately to face any load scenarios.
The ability to start different kind of processes anywhere (since they are stateless, IV. Processes) makes the app highly resilient, flexible, and especially suited for cloud environments.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
From IV. Processes and VIII. Concurrency, it follows that processes are disposable resources. As such, they must be able to start quickly and handle both planned and spurious shutdowns gracefully - by leaving the system in a consistent state.
Graceful shutdown is achieved by exiting properly upon a termination signal. Handling crashes properly is eased by the fact that processes are stateless.
For example, a worker should either finish or return the current task to the queue upon a termination signal. The queuing system should re-enqueue any unfinished tasks after a given timeout so the sudden death of a worker is not an issue.
Disposability is the cornerstone that lets you scale processes at will without fear. It guarantees your system stays robust and coherent without losing flexibility.
X. Dev/prod parity
Keep development, staging, and production as similar as possible
The gaps between environments should be kept as low as possible. The goal is to minimize the differences in time (how long it takes to deploy a change in production), personnel (people involved in developing and deploying the app), and tools (software, infrastructure/backing services).
Especially for backing services, ensure you use the same service type and versions in all environments. It may come in different flavors (e.g. a simple docker container running postgres:15 locally, a fully-pledged RDS 15.7 on prod), but the version and protocols should be aligned.
This principle shares many similarities with the agile and DevOps movements, both of which have demonstrated significant benefits across all aspects of the software lifecycle.
XI. Logs
Treat logs as event streams
An app should log information to the standard output (stdout) as an ephemeral stream and delegate the log management to the execution environment.
This way, it is up to each execution environment to decide what to do with logs. In production, you may have one or more log aggregators pushing data to external data sources (ElasticSearch, LogStash, Kafka, …) for monitoring and event detection, while locally, developers can just tail the logs.
All advanced log management tools can hook to stdout. On the other hand, an app logging to a file requires a filesystem (so not stateless) and makes it harder to access the logs. In short, do not limit the possibilities by complexifying your code. A simple print (with timestamps) will do!
XII. Admin processes
Run admin/management tasks as one-off processes
We often need to run on-off administrative or maintenance tasks such as migrating data, clearing the cache, re-indexing content, or simply executing arbitrary code to get data or understand the system.
The Twelve-Factor app recommends always running those tasks against a release, (V. Build, release, run) using the same codebase and config as the other regular processes. A containerized application makes it easier, as we can spin up a new container alongside the app with the exact same config for one-off purposes.
To avoid synchronization issues, admin code meant to run more than once should also ideally be part of the codebase.
For this purpose, frameworks and languages shipping with a REPL (Read Eval Print Loop) shell have a strong advantage. A good example is Django, which provides the ./manage.py shell utility and makes it easy to register custom management commands that run with the same ./manage.py entrypoint (I abuse its power, even in production). Ruby and NodeJS have similar mechanisms.
The Twelve-Factor, similar to Design Patterns, is here to answer common problems so we do not constantly reinvent the wheel.
These best practices may seem obtuse, but if you pay attention, you’ll notice that many well-designed apps adhere to these principles, knowingly or not. Detect them in the wild and apply them until they become second nature. From my experience, you won’t regret it!
Let me know if you’d like a follow-up article using a project to exemplify those principles and how to put them into use, and happy coding :).