
bitdowntoc is a Markdown TOC - Table of Contents - generator I have been developing for a while now. You can copy your markdown, click generate, and have a nice Table of Contents inserted wherever you want. I recently added a “devto” profile, which tries to reuse the anchors already generated by dev.to for headings. This forced me to dig into dev.to anchors generation, and oh boy, it’s a mess.
This article explains part of the challenge and digs further into one specific pain point: emojis. For those interested, the full anchor generation implementation for dev.to is available here. Try it yourself → bitdowntoc (use the devto profile).
What exactly are anchors
Let’s say you add the following heading to your article markdown:
## Hello dev.to!When you preview or save it on dev.to, it becomes:
<h2>
<a name="hello-devto" href="#hello-devto"></a>
Hello dev.to!
</h2>As you can see, dev.to automatically adds a <a> with a name attribute. The latter is called an anchor: the hello-devto can be used in a fragment link for navigation, using hashtag + anchor: #hello-devto (see Finally a clean and easy way to add a table of contents to dev.to articles dev.to articles for more information).
To generate a table of contents for dev.to, you thus need to know how those anchors are generated, to point to the right fragment link.
The mess of dev.to anchors
Since dev.to is based on forem, which is open-source, it wasn’t difficult to find the exact code used to generate anchors. Here it is (html_rouge.rb):
# .. other pre-processing ...
def slugify(string) # here, string = heading title (pre-processed)
stripped = ActionView::Base.full_sanitizer.sanitize string
stripped.downcase
.gsub(EmojiRegex::RGIEmoji, "").strip
.gsub(/[[:punct:]]/u, "")
.gsub(/\s+/, "-")
endThis code goes through the following steps (simplified):
-
it sanitizes the title using a forem function. Sanitizing means stripping HTML tags, to make the content safe;
-
it lowercases the whole string (
.downcase); -
It strips the emojis using a Ruby library called emoji_regex, which is based upon a javascript library of the same name;
-
It removes the punctuations with a regex made of a POSIX character class;
-
It replaces (consecutive) spaces with dashes.
It seems rather straightforward, right? But as easy as it looks, it yields some very, very, strange results. Don’t believe me? Have a look at the following markdown document, and try to come up with a valid Table of Content for dev.to:
# Hello dev.to!
# Kotlin is `fun`
# `<hello href="http://link.me">` <hello> `&%£`
# `<hello>` <world> `&`
# space 😃
# ' ' ʻ ՚ Ꞌ ꞌ ′ ″ ‴ 〃 " ˮ
# 'Hello' means ˮBonjourˮ en français héhé
# ☻ emojis 😆 😊 🕊 ☮ ✌ ☕
# html? <0>
# Check out [bitdowntoc](https://bitdowntoc.ch), It is *awesome*!Here is what a valid Table of Content should look like:
- [Hello dev.to!](#hello-devto)
- [Kotlin is `fun`](#kotlin-is-raw-fun-endraw-)
- [`<hello href="http://link.me">` <hello> `&%£`](#-raw-lthello-hrefhttplinkmegt-endraw-raw-amp£-endraw-)
- [`<hello>` <world> `&`](#-raw-lthellogt-endraw-raw-amp-endraw-)
- [space 😃](#space)
- [' ' ʻ ՚ Ꞌ ꞌ ′ ″ ‴ 〃 " ˮ](#-ʻ-ꞌ-ꞌ-ˮ)
- ['Hello' means ˮBonjourˮ en français héhé](#hello-means-ˮbonjourˮ-en-français-héhé)
- [☻ emojis 😆 😊 🕊 ☮ ✌ ☕](#☻-emojis-🕊-☮-✌)
- [html? <0>](#html-lt0gt)
- [Check out bitdowntoc, It is *awesome*!](#check-out-bitdowntoc-it-is-awesome)Note: this table of content was entirely generated by bitdowntoc, except the “html? <0>” one. In its current implementation, bitdowntoc would actually generate the anchor “html”, which doesn’t work. But everything else is supported!
One word: wow. What is this #-raw-lthellogt-endraw-raw-amp-endraw- ?? Just to give you an idea, both GitHub and GitLab will generate a simple #hello for the same title!
Pseudo-code
I won’t go into the details here (I tried writing a comprehensive article, and it was way too long), but for you to better understand how this mess came up to be, here is how you could re-implement the logic (the order matters):
-
🤯 inline code (in backticks) is handled differently than the rest. Take all content between backticks, and escape HTML entities in it (
&becomes&,<becomes<etc) -
strip all remaining HTML tags (
<hello>,<a href="hello">,</hello>, etc). This of course doesn’t apply to the escaped sequences in 1) -
handle markdown links: constructs such as
[link text](URL)are stripped to keep onlylink text -
🤯 escape the remaining HTML entities (beware of not escaping twice! The
&in 1 should NOT become&&amp;) -
🤯🤯🤯🤯 remove some of the emojis (yup, I said some. Keep reading!)
-
trim: remove leading and trailing spaces
-
🤯 replace all backticks pairs with
-raw-and-endraw-(`hello`becomes-raw-hello-endraw-) -
remove all punctuation characters (well, not all, some quotes and other punctuations are kept, I will let you figure out which)
-
replace all (consecutive) spaces with a single dash (same as GitLab).
Most of the weird stuff comes from steps 1, 4, and 7 - and emojis!
Terms of the challenge
Kotlin MPL - basic code only!
bitdowntoc is entirely written in Kotlin and offers both a command line (a JAR) and a web interface. To avoid repeating the logic twice, most of the code is part of a Kotlin Common module, which I reuse in both a Kotlin JVM and a Kotlin JS module. This is part of Kotlin Multi-Platform (Kotlin MP).
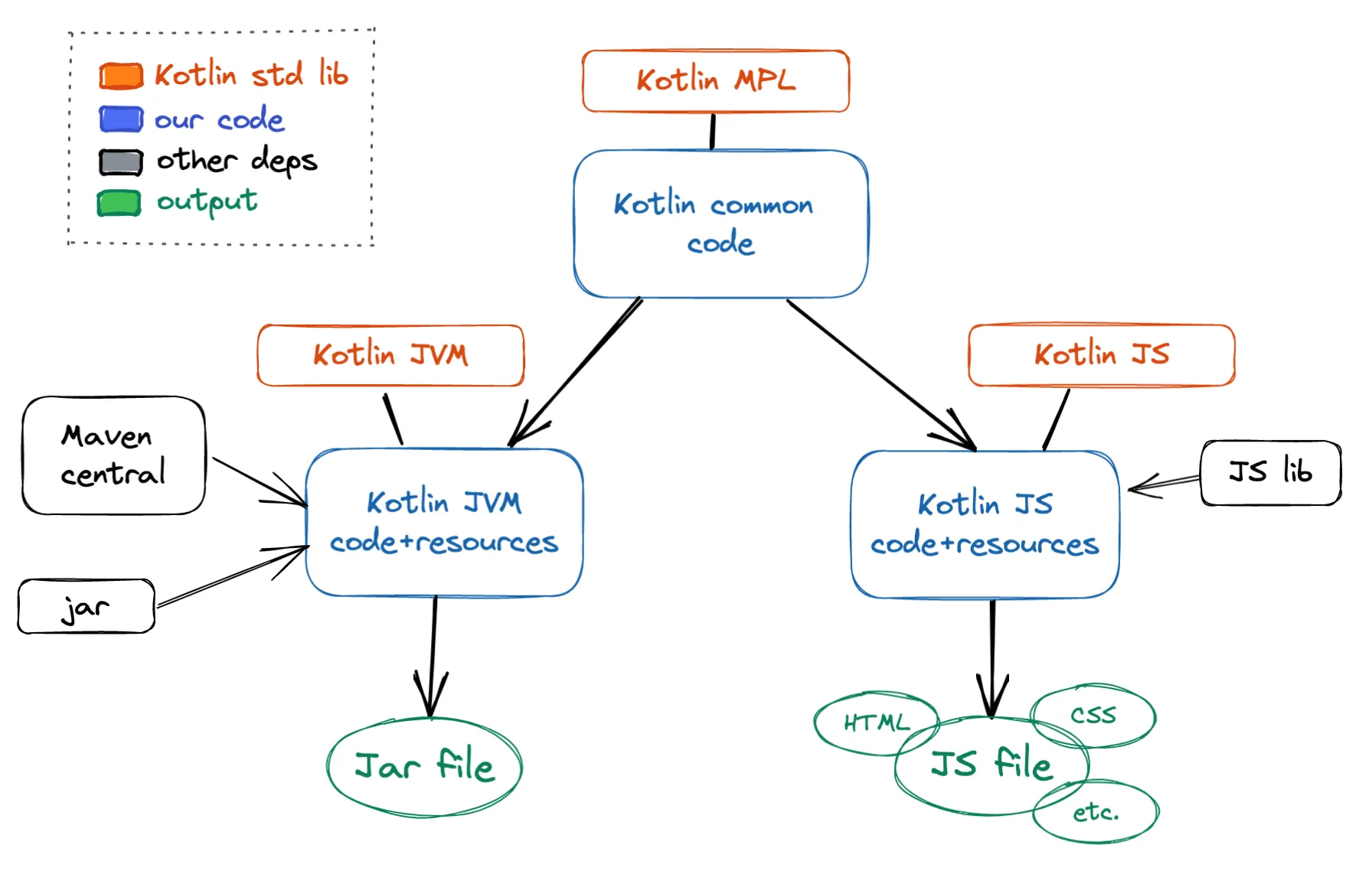
To be executable on different platforms, the common module is written in a way that is independent of the underlying runtime. How is this possible you ask? Because common code uses only a subset of the Kotlin language - the Kotlin Multiplatform Language (Kotlin MPL) - which provides a limited set of APIs and constructs that are guaranteed to be supported by all Kotlin Multiplatform languages.
Kotlin MPL - simple regexes only!
For my project, the most significant limitation of Kotlin MPL is regular expressions (regexes). Kotlin Common aims at interoperability and platform agnosticism. To support regexes, it thus provides a wrapper called Regex, which takes a string as a single parameter. This string, say .*, is then “copy-pasted” inside a Pattern in java - Pattern.compile(".*") - and a RegExp object in javascript with the Unicode flag - /.*/u. Do you see the problem here?
It means any regex that you use in common code must:
-
be supported by both the Java and JS implementations, and
-
be interpreted the same by both engines.
Java supports the \p{Latin} character range, while javascript supports the \p{Emoji}. Java requires all special characters to be escaped with double backslashes, JS requires only one backslash. The more complex the regex, the higher the chance corner cases will be handled differently.
So in short, I can only rely on very simple regexes: no fancy character classes!
How I ended up stripping emojis
Contrary to other platforms, dev.to doesn’t treat emojis like any other special character (that is, just stripping them all). Take this:
# ☻ emojis 😆 🕊 ☮ 😊 ✌ ☕ 🌽 ♥This is the generated anchors for different platforms:
| platform | anchor |
|---|---|
| dev.to | ☻-emojis-🕊-☮-✌-♥ |
| github | emojis------- |
| gitlab | -emojis- |
Why those emojis and not all? This is because dev.to handles emojis separately using a ruby library called emoji_regex. Here is its full library documentation:
EmojiRegex::RGIEmojiis the regex you most likely want. It matches all emoji recommended for general interchange, as defined by the Unicode standard’sRGI_Emojiproperty.
Looking at the Unicode standard:
ED-27. RGI emoji set — The set of all emoji (characters and sequences) covered by ED-20, ED-21, ED-22, ED-23, ED-24, and ED-25.
This is the subset of all valid emoji (characters and sequences) recommended for general interchange.
This corresponds to the RGI_Emoji property.
Follow the links if you are interested, you’ll see that it doesn’t help a lot. You get huge txt files, with lots of “if this emoji is followed by … but not … and …” mumbo jumbo. I was overwhelmed with information, yet couldn’t find a simple list of all emojis falling into those categories.
I tried many different things - remember that I cannot use regex character classes, even though one exists in Javascript (\p{Emoji} ). I tried to understand the logic, use Unicode groups in regexes, and even use different regexes depending on the platform (JS/JVM) with some nasty tricks. All in vain.
The epiphany 💡 came after a long day of trial and error:
-
let’s find a list of all emojis - ideally in the form of a regex (I used the one from https://github.com/sweaver2112/Regex-combined-emojis)
-
paste it into a dev.to heading,
-
hit preview and see which emojis are still present in the generated anchor,
-
remove the emojis still in the anchor (3) from the regex (1).
Jackpot!
In Kotlin code:
fun main() {
// copy from https://github.com/sweaver2112/Regex-combined-emojis,
// then add "|" at the beginning and end of the string
val allEmojis =
"|\uD83E\uDDD1\uD83C\uDFFB\u200D❤️\u200D\uD83D\uDC8B\u200D\uD83E\uDDD1\uD83C\uDFFC|...|▫|"
// paste the allEmojis to a dev.to title,
// take the resulting anchor,
// add "|" between each emoji
// (I used Sublime Text with find: "(.*)", replace: "|\1")
val keptEmojis =
"\uD83D\uDD73|...|▫"
val finalRegex = keptEmojis
.split("|")
.map { "|$it|" } // whole matches !!!
.fold(allEmojis) { acc, it -> acc.replace(it, "|") }
.replace(Regex("\\|+"), "|")
.trim('|')
println(finalRegex)
// the result is the removeEmojisRegex
}The final regex is a bit long though, 13,226 characters 🤪, but it does the job. It isn’t even slow during matching!
private val removedEmojisRegex = Regex(
"🧑🏻❤️💋🧑🏼|🧑🏻❤️💋🧑🏽|...|🥭|🍎|🍏|...|Ⓜ|⚫|⚪|⬛|⬜|◾|◽"
)
title
// ... sanitize ...
.replace(removedEmojisRegex, "")The regex even takes into account the emoji modifiers. The first two blocks (separated by |), actually represent the emojis 🧑🏻❤️💋🧑🏼 and 🧑🏻❤️💋🧑🏽 (kiss with different skin tones).
And this is how I completed the challenge, proof that brute force is sometimes the right option, even though it may crash your IDE… 12K+ character long strings with Unicode aren’t especially liked by IntelliJ!
PS: this article is a bit different than my previous ones, let me know if this kind of format is of interest to you! I may have other “challenges” in stock. As always, a like or comment would help me keep my motivation up ☻.